Interpolation von Höhenprofilen
Man kennt sie von der Planung von Wanderungen oder Radtouren: Höhenprofile entlang eines bestimmten Streckenverlaufs.
Sie geben Auskunft über zurückgelegte Höhenmeter, Steigungen entlang der Strecke oder Maxima und Minima der Höhe. Doch nicht nur im Alltag spielen Höhenprofile eine Rolle. Im öffentlichen Verkehr können sie zum Beispiel bei der Planung von Standorten für Lade-Stationen im Rahmen des Einsatzes von batteriebetriebenen Verkehrsmitteln helfen. Denn die benötigte Antriebsleistung hängt stark vom Höhenprofil der zurückzulegenden Strecke ab.
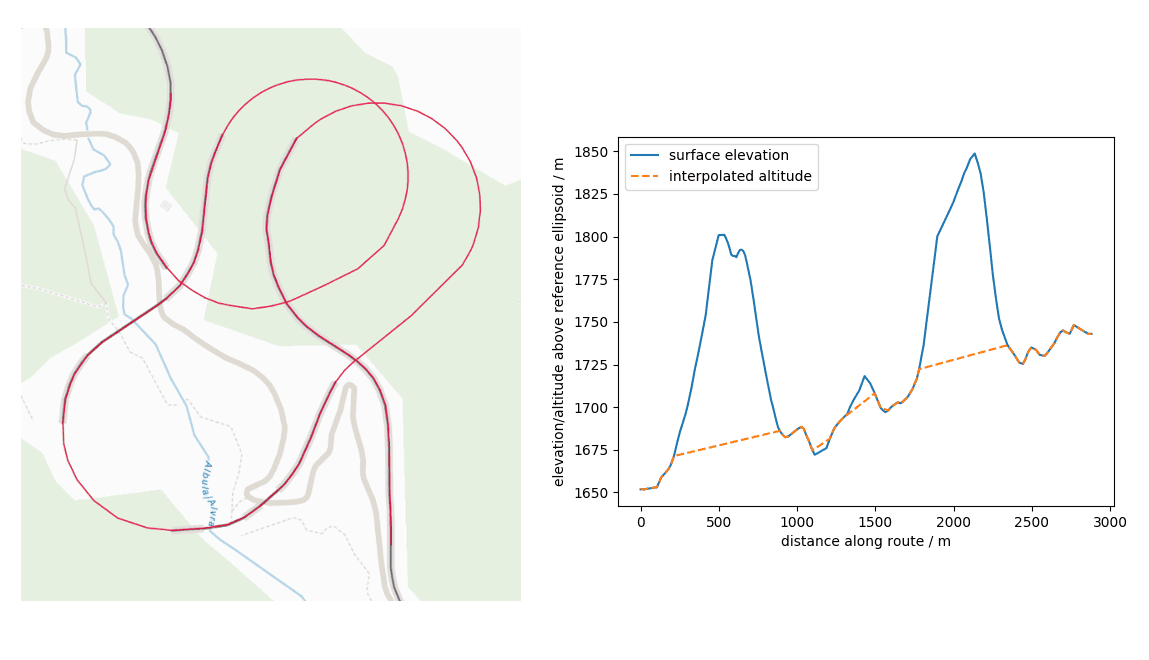
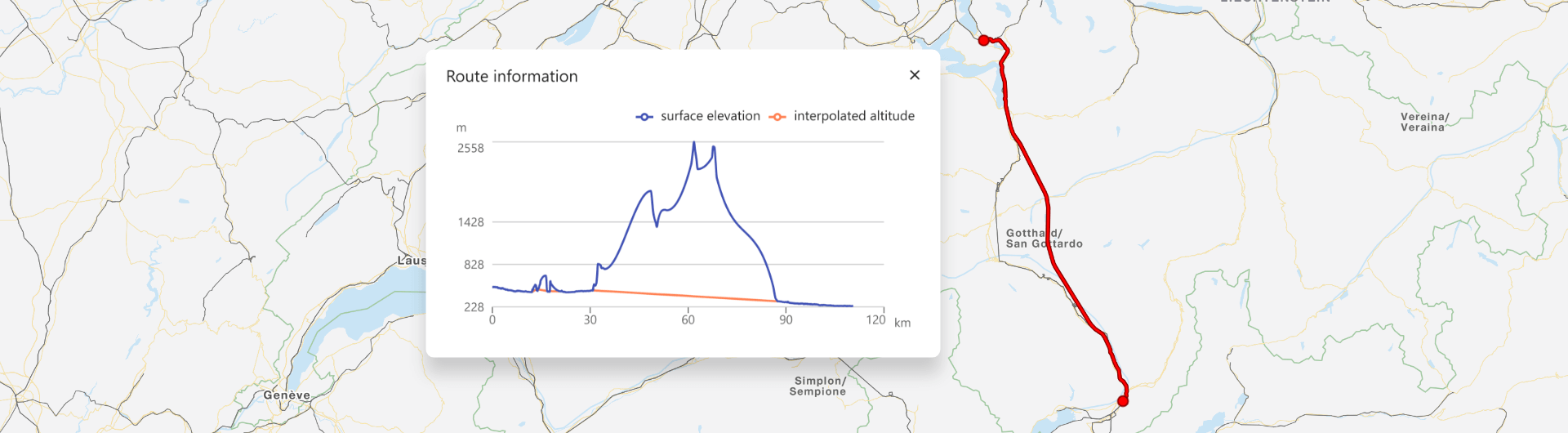
Abbildung 1: Beispiel für einen Streckenverlauf mit dazugehörigem Höhenprofil
Doch wie kommt man von einer einfachen Anfrage wie fahre von A über B nach C mit Verkehrsmittel X zu einem Streckenverlauf mit Höhenprofil? Am besten gehen wir der Reihe nach vor:
Bestimmen des Streckenverlaufs
Der erste Schritt besteht darin, den Streckenverlauf zu bestimmen. Hierfür haben wir bei geOps bereits eine funktionierende Lösung etabliert: Die Route API. Weitere Informationen hierzu finden sich in unserem Developer Portal Die Ausgabe dieser Schnittstelle besteht im Wesentlichen aus einer geordneten Abfolge von 2D-Koordinaten auf einer idealisierten Erdoberfläche, oder genauer gesagt dem WGS84-Referenz-Ellipsoid. Das Ausgabeformat ist hierbei GeoJSON.
Der Route-Decorator-Dienst
Nun gilt es, diese Trajektorien mit Zusatzdaten anzureichern. Denn neben den Höhenwerten muss zum Beispiel auch die zurückgelegte Strecke berechnet werden. Zu diesem Zweck haben wir einen in sich abgeschlossenen Zusatz-Dienst, den sogenannten Route-Decorator entwickelt. Dabei handelt es sich um ein Python-Backend (mit Flask umgesetzt) mit einer simplen Schnittstelle, welche ein GeoJSON annimmt und mit gewünschten Zusatzinformationen angereichert wieder zurück liefert. Eine modulare Struktur sorgt dafür, dass neue Programmteile zur Berechnung verschiedener Zusatzinformationen leicht ergänzt werden können.
Der Vorteil der Umsetzung als in sich abgeschlossener Dienst liegt darin, nicht nur Ausgaben des eigenen Routing-Backends anreichern zu können, sondern im Prinzip beliebige GeoJSON-Eingaben. Den Preis, den man für diese Flexibilität zahlt, sind Einbußen bei der Performance. Denn die Höhenwerte müssen zum Beispiel für jede Anfrage aus einer Datenbank extrahiert werden und sind nicht direkt als Zusatzinformation im Routing-Backend hinterlegt.
Höhendaten ergänzen
Für die Höhenwerte verwenden wir derzeit Daten aus der Shuttle Radar Topography Mission (SRTM) . Diese haben wir in Raster-Kacheln in einer PostgreSQL-Datenbank mit PostGIS Raster hinterlegt. Würde man diese Pixel-Daten zum Beispiel nur mittels einer Abfrage des nächstgelegenen Messwerts direkt verwenden, ergäben sich aufgrund der begrenzten örtlichen Auflösung unnatürliche Sprünge in den resultierenden Höhenprofilen. Daher werden für jeden Eingangs-Punkt die vier nächsten Nachbarn aus der Datenbank abgefragt und der Höhenwert wird mittels bilinearer Interpolation berechnet. Die bilineare Interpolation lässt sich als ein Skalar-Produkt eines Vektors a mit einer Matrix M angewandt auf einen anderen Vektor b schreiben, was einer Auswertung einer Bilinearform entspricht. Die interpolierten Höhen lassen sich also schreiben als:
Da ein Streckenverlauf aus vielen Punkten bestehen kann (z.B. N= 10000), kommt hierfür NumPy zum Einsatz. Für alle, die NumPy noch nicht kennen, hier ein kleiner Code-Schnipsel als Appetit-Anreger für eine Möglichkeit, wie man viele Bilinearformen in einem Rutsch auswerten kann, ohne eine langsame Python-Schleife zu verwenden:
numpy.einsum(
"im,imn,in->i", # sum (a_im * M_imn * b_in) over m and n, but not i
a_im, # datastructure containing multiple vectors
M_imn, # multiple matrices
b_in, # multiple vectors
out=coords[:, 2], # write output directly to z-component of coordinates
)Der Flaschenhals ist hierbei letztendlich die Datenbank-Abfrage, welche zum Erzeugen der Eingangs-Vektoren und -Matrizen verwendet wird.
Tunnel und Brücken
An dieser Stelle wären wir eigentlich fertig, gäbe es nicht diese Erfindungen namens Tunnel und Brücken. Denn schlussendlich ist man natürlich am Höhenprofil entlang der verwendeten Infrastruktur (Straße / Schiene) interessiert. Bekanntlich können Straßen und Schienen über Brücken und durch Tunnel führen und die Höhenunterschiede zwischen natürlicher Erdoberfläche und Infrastruktur kann mitunter gravierend sein. Mit unserem getrennten Ansatz gilt es dabei gleich zwei Probleme zu lösen:
- Erkennen, wo eine Route durch einen Tunnel oder über eine Brücke fährt
- Höhendaten für diese Abschnitte der Route korrigieren
Als Datengrundlage dient uns hierfür OpenStreetMap (OSM). Die OSM-Daten werden in einem Pre-Processing-Schritt aufbereitet. Zunächst wird ein Graph aller OSM-Ways erstellt, welche als Brücke oder Tunnel klassifiziert sind. Jede Zusammenhangskomponente dieses Graphs nennen wir ein Netzwerk. Aus diesen Netzwerken lassen sich Geometrien erstellen, welche zur Erkennung, ob die Route durch einen Tunnel oder über eine Brücke fährt, genutzt werden können.
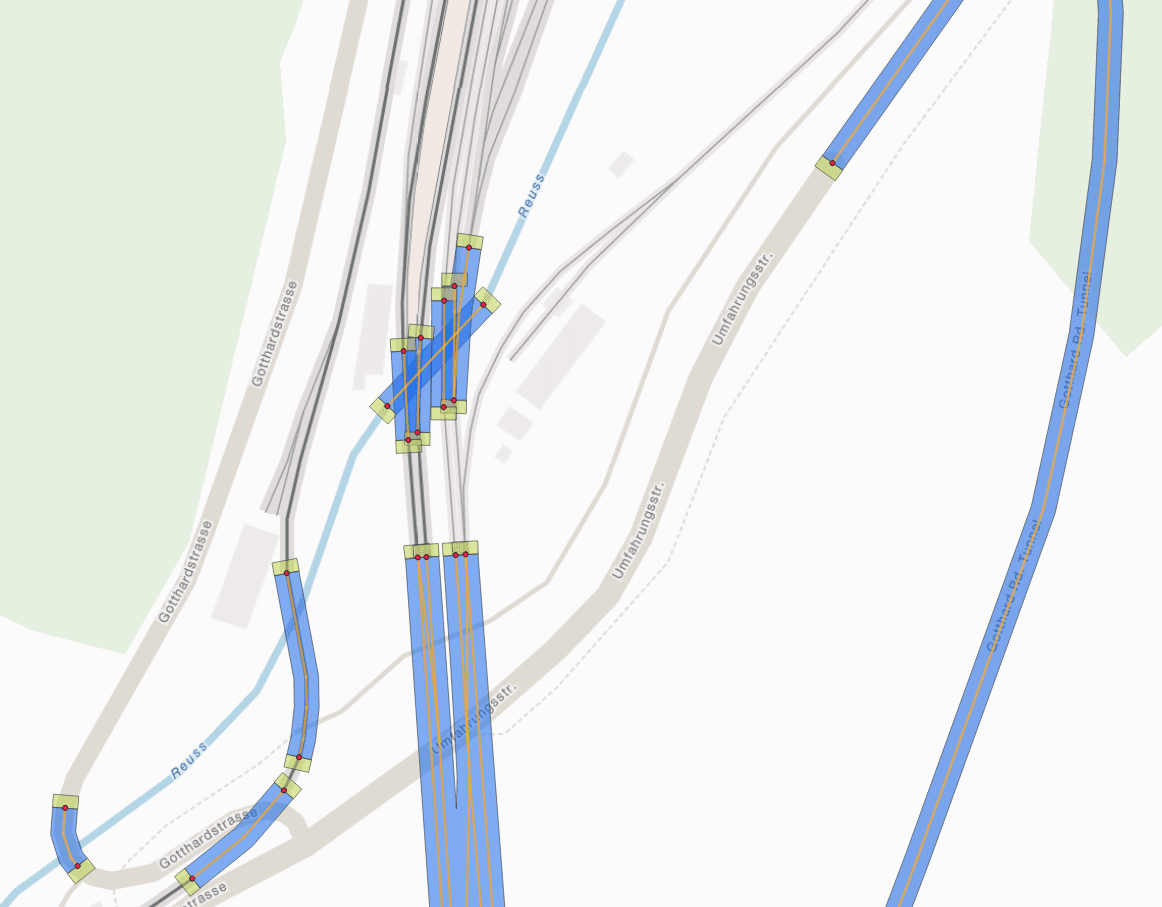
Abbildung 2: Geometrien der Tunnel/Brücken-Netzwerke aus OSM-Daten: Blau: Netzwerk-Polygon. Grün: Eingangs-Polygon. Rot: Eingangs-Punkt. Orange: Liniengeometrie mit interpolierten Höhendaten.
Bei der Erkennung muss berücksichtigt werden, dass mehrere Netzwerk-Polygone sich überlappen können (zum Beispiel bei teils parallelen Tunneln für Hin- und Rückrichtung). Ferner kann eine Route ein Netzwerk-Polygon schneiden, ohne durch einen Eingang zu fahren, zum Beispiel bei einer Straße, die unter einer Brücke hindurch führt. Es ist also wichtig, dass sowohl der Verlauf des Tunnels oder der Brücke als auch die dazugehörigen Eingänge im Entscheidungsprozess berücksichtigt werden. Für die Auflösung von Konflikten bei mehreren möglichen Tunneln verwenden wir einen iterativen Ansatz, welcher es erlaubt, Cluster sich gegenseitig überlappender Netzwerke mittels eines Rankings schrittweise aufzulösen. Als Messgröße für das Ranking dient hierbei der Abstand der Route zu den jeweiligen Eingängen. Hat man nun die passenden Tunnel und Brücken gefunden, so kann man die Vertices der Route auf die nächstgelegenen Linien-Segmente der zugeordneten Netzwerke projizieren und die Höhe durch lineare Interpolation entlang der Wegstrecke zwischen den bekannten Höhen am Anfang und Ende des jeweiligen Segments gewinnen.
Es verbleibt die Frage, woher die hier als bekannt vorausgesetzten Höhenwerte innerhalb eines Tunnel/Brücken-Netzwerks kommen. Treten wir einen Schritt zurück und formulieren das Problem etwas abstrakter: Gegeben ein zusammenhängender, ungerichteter Graph mit bekannten Werten für die Höhe an gewissen Knoten (Eingänge) und bekannten Weglängen entlang der Kanten: Was ist eine gute Schätzung für die Höhenwerte an allen Knoten, die keine Eingänge sind? Für einen einfachen Tunnel mit nur zwei Eingängen liegt die Lösung auf der Hand: Linear zwischen beiden Eingängen entlang der Wegstrecke interpolieren. Doch was ist eine gute Verallgemeinerung für Tunnelsysteme mit mehr als zwei Eingängen und Kreuzungen/Weichen, welche in der Realität sehr häufig auftreten?
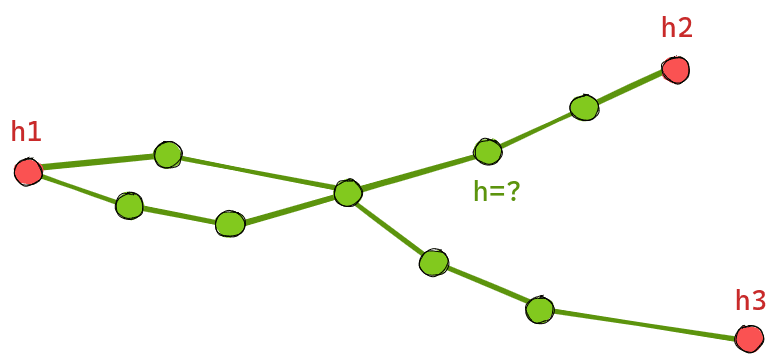
Abbildung 3: Graph mit bekannten Höhen (rot) und unbekannten Höhen (grün)
Unser Bauchgefühl sagt uns: Irgendwie müssen unnötige Steigungen vermieden werden. Dieses Bauchgefühl lässt sich in eine Kostenfunktionf gießen, welche einem Graph die mit den Kantenlängen gewichteten Kantensteigungen zuordnet. Scheut man sich nicht, auch mal Papier und Bleistift in die Hand zu nehmen, so kommt man nach einigen Umformungen zum Schluss, dass solch eine Kostenfunktion genau dann minimiert wird, wenn an jedem Knoten mit unbekannter Höhe die Summe der einlaufenden Kantensteigungen verschwindet. Auch ein Blick auf das triviale Beispiel der linearen Interpolation zeigt, dass dies hiermit konsistent ist, denn an jedem Punkt einer Geraden geht es links davon genauso steil den Berg hoch, wie es rechts den Berg runter geht, um es salopp auszudrücken. Netterweise lässt sich diese Minimierungs-Bedingung als lineares Gleichungssystem schreiben, das heißt man findet eine Matrix A und einen Vektor x, so dass für den Vektorh der gesuchten Höhen gilt:
![]()
Die numerische Lösung hiervon ist mit Numpy ein Einzeiler:
# h: vector of unknown elevations
# matrix A and vector x depend on edge lengths, graph topology and known elevations
h=numpy.linalg.solve(A, x)Für die Verarbeitung der Graphen kommt NetworkX zum Einsatz.
Damit haben wir also alle Komponenten beisammen, um für einen gegebenen Streckenverlauf ein Höhenprofil entlang der verwendeten Infrastruktur des Verkehrsmittels zu erzeugen. In Abbildung 1 ist ein nach dieser Methodik erzeugtes Höhenprofil beispielhaft dargestellt. Wer es selbst einmal ausprobieren möchte, kann dies in unserer Routing-Demo tun: Start und Ziel wählen und dann auf Route information klicken.
Die Methode ließe sich sogar dahingehend erweitern, dass nicht nur die Eingänge als Knoten bekannter Höhe verwendet werden. Ist mehr über einen bestimmten Tunnel oder eine bestimmte Brücke bekannt (z.B. die Höhe an einem Scheitelpunkt), so kann diese Information ebenfalls in das lineare Gleichungssystem einfließen.
Lessons Learned
Manchmal lohnt es sich, einen Schritt zurück zu treten, und ein Problem zunächst mit Papier und Bleistift anzugehen. Im Python-Universum hat man dabei mit NumPy und NetworkX mächtige Werkzeuge an der Hand, welche die Verbindung vom Papier zurück zum Code auf elegante Art herzustellen vermögen.